chatgpt已经从年前到现在已经火出了天际,直接颠覆了整个行业,于是乎各个大厂开始入局,比速度,目前质量上会往后靠,先从无到有的折腾。chatgpt说实在的有点惭愧,我没有申请账号,
不过呢偶然在群里看到大家分享微信的AI,WELM,于是我就申请了token,具体怎么样还不知道,不过可以先把申请步骤告诉大家。
welm介绍
官网介绍WeLM 提供续写功能,但并不具有原生对话能力,WeLM 是一个非常擅长理解和生成文本的通用语言模型。你可以通过调用 WeLM 的 API 解决多种多样涉及文本的任务。
举例说明
如果你给的 prompt 是
我今天很模型也许会返回文本:“开心,因为看了一本书。”。
如果你给的 prompt 是,
问题:百年孤独的作者是?\n 回答:模型也许会返回文本:“加西亚·马尔克斯”。
申请方法
步骤一:登录官网
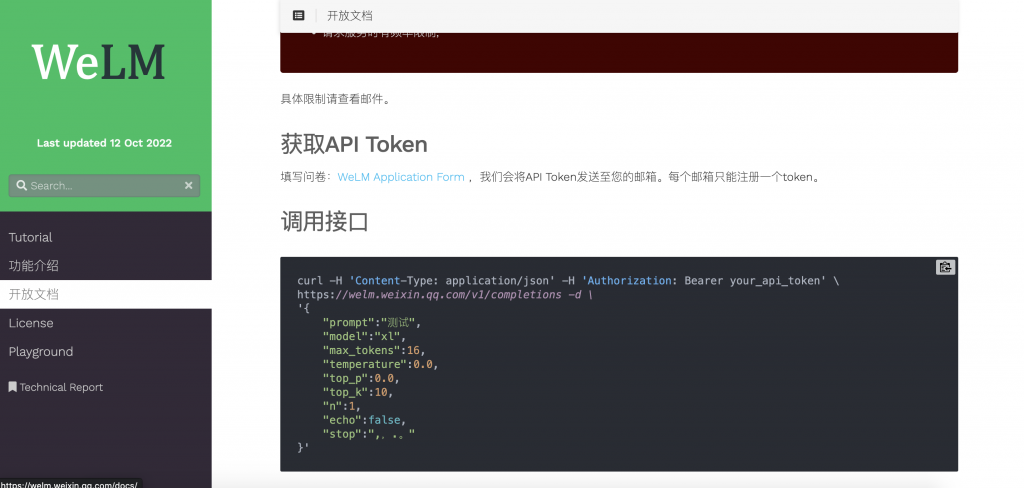
步骤二:填写问卷调查
我这里使用了QQ邮箱,但是需要等待,时间有点长,我从申请到收到邮件大概半天吧。
申请成功邮件

PHP调用
function query_api($prompt, $model, $max_tokens, $temperature, $top_p, $top_k, $n, $echo, $stop, $token)
{
$url = "https://welm.weixin.qq.com/v1/completions";
$data = array(
"prompt" => $prompt,
"model" => $model,
"max_tokens" => $max_tokens,
"temperature" => $temperature,
"top_p" => $top_p,
"top_k" => $top_k,
"n" => $n,
"echo" => $echo,
"stop" => $stop
);
$data = json_encode($data);
$headers = array(
"Content-Type: application/json",
"Authorization: Bearer " . $token
);
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_URL => $url,
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => "",
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 30,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => "POST",
CURLOPT_POSTFIELDS => $data,
CURLOPT_HTTPHEADER => $headers,
));
$response = curl_exec($curl);
$err = curl_error($curl);
curl_close($curl);
if ($err)
{
echo "请求失败: " . $err;
return null;
}
else
{
$result = json_decode($response, true);
return $result;
}
}
$prompt = "测试";
$model = "xl";
$max_tokens = 16;
$temperature = 0.0;
$top_p = 0.0;
$top_k = 10;
$n = 1;
$echo = false;
$stop = ",,.。";
$token = "你的token";
$result = query_api($prompt, $model, $max_tokens, $temperature, $top_p, $top_k, $n, $echo, $stop, $token);
Request body
model: string 必选,要使用的模型名称,当前支持的模型名称有medium、 large 和 xl
prompt: string 可选,默认值空字符串,给模型的提示
max_tokens: integer 可选,最多生成的token个数,默认值 16
temperature: number 可选 默认值 0.85,表示使用的sampling temperature,更高的temperature意味着模型具备更多的可能性。对于更有创造性的应用,可以尝试0.85以上,而对于有明确答案的应用,可以尝试0(argmax采样)。 建议改变这个值或top_p,但不要同时改变。
top_p: number 可选 默认值 0.95,来源于nucleus sampling,采用的是累计概率的方式。即从累计概率超过某一个阈值p的词汇中进行采样,所以0.1意味着只考虑由前10%累计概率组成的词汇。 建议改变这个值或temperature,但不要同时改变。
top_k: integer 可选 默认值50,从概率分布中依据概率最大选择k个单词,建议不要过小导致模型能选择的词汇少。
n: integer 可选 默认值 1 返回的序列的个数
echo: boolean 可选 默认值false,是否返回prompt
stop: string 可选 默认值 null,停止符号。当模型当前生成的字符为stop中的任何一个字符时,会停止生成。若没有配置stop,当模型当前生成的token id 为end_id或生成的token个数达到max_tokens时,停止生成。合理配置stop可以加快推理速度、减少quota消耗。
Response
{
"id":"25ade274-2f8a-11ed-8c3d-1767c0ccef73",
"object":"text_generation",
"created":1662650590,
"model":"xl",
"choices":[
{
"text":"测试结果",
"index":0,
"logprobs":0,
"finish_reason":"finished",
}
]
}状态码
当请求出现错误时,通过校验http state code 可以查看错误原因
超时:504
服务不可用:503
用户prompt命中敏感词:400, finish_reason: “error: content policy violation”
生成结果命中敏感词:200, finish_reason: “error: internal error”
用户输入参数不合法:400, finish_reason返回原因
配额超限制:429, response body: “quota limit exceed”
请求频率超限制:429, response body: “rate limit exceeded”