今天给大家推荐的是小红书作品的采集程序,和之前抖音采集下载的是同一个作者,在此向此作者致敬。
项目功能
采集小红书图文 / 视频作品信息
提取小红书图文 / 视频作品下载地址
下载小红书无水印图文 / 视频作品文件
支持 Tampermonkey 用户脚本
批量下载账号作品(搭配用户脚本)
自动跳过已下载的作品文件
作品文件完整性处理机制
自定义图文作品文件下载格式
持久化储存作品信息至文件
作品文件储存至单独文件夹
后台监听剪贴板下载作品
支持 API 调用功能
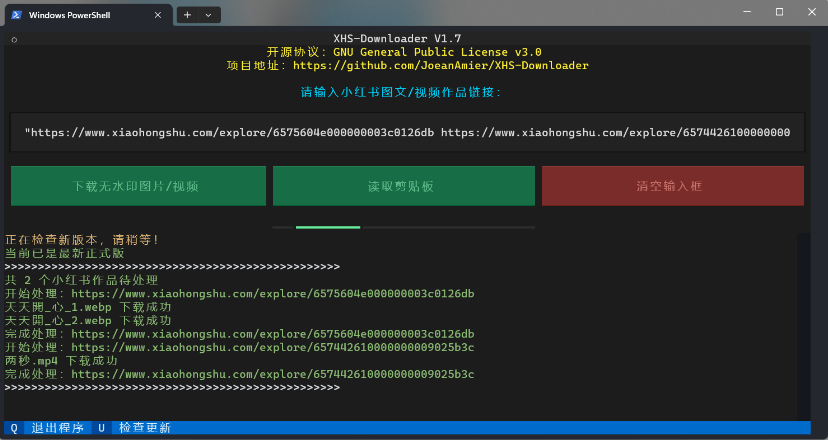
演示截图
支持链接
– `https://www.xiaohongshu.com/explore/作品ID`
– `https://www.xiaohongshu.com/discovery/item/作品ID`
– `https://xhslink.com/分享码`
支持单次输入多个作品链接,链接之间使用空格分隔。
源码运行
1. 安装版本号不低于 `3.12` 的 Python 解释器
2. 运行 `pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt` 命令安装程序所需模块
3. 下载最新的源码至本地
4. 运行 `main.py` 即可使用
二次开发
若要二次开发,可以根据 `main.py` 的注释提示进行代码调用或修改!
# 示例链接
error_link = "https://www.viphper.com"
demo_link = "https://www.xiaohongshu.com/explore/xxxxxxxxxx"
multiple_links = f"{demo_link} {demo_link} {demo_link}"
# 实例对象
work_path = "D:\\" # 作品数据/文件保存根路径,默认值:项目根路径
folder_name = "Download" # 作品文件储存文件夹名称(自动创建),默认值:Download
user_agent = "" # 请求头 User-Agent
cookie = "" # 小红书网页版 Cookie,无需登录
proxy = None # 网络代理
timeout = 5 # 请求数据超时限制,单位:秒,默认值:10
chunk = 1024 * 1024 * 10 # 下载文件时,每次从服务器获取的数据块大小,单位:字节
max_retry = 2 # 请求数据失败时,重试的最大次数,单位:秒,默认值:5
record_data = False # 是否记录作品数据至文件
image_format = "WEBP" # 图文作品文件下载格式,支持:PNG、WEBP
folder_mode = False # 是否将每个作品的文件储存至单独的文件夹
async with XHS() as xhs:
pass # 使用默认参数
async with XHS(work_path=work_path,
folder_name=folder_name,
user_agent=user_agent,
cookie=cookie,
proxy=proxy,
timeout=timeout,
chunk=chunk,
max_retry=max_retry,
record_data=record_data,
image_format=image_format,
folder_mode=folder_mode,
) as xhs: # 使用自定义参数
download = True # 是否下载作品文件,默认值:False
# 返回作品详细信息,包括下载地址
print(await xhs.extract(error_link, download)) # 获取数据失败时返回空字典
print(await xhs.extract(demo_link, download))
print(await xhs.extract(multiple_links, download)) # 支持传入多个作品链接一定要记住我们学习别人开源程序的目的,是提升思路,扩充自己,将别人的思路转换为自己的,多看开源的项目,可以快速提升自己的能力。